0. 들어가며
BloomFilter에 대해 알아보게 된 계기
대규모 사용자 기반을 가진 서비스에서 사용자들에게 개인화된 정보를 제공하는 경우, 개인화된 정보를 효율적으로 저장하고 이를 빠르게 처리해야하는 것이 중요합니다. 하지만 DB만을 저장소로 사용하다보면 데이터가 쌓일수록 저장공간도 많이 사용해야하고, 트래픽이 많아질 수록 성능 저하가 생길 수 있습니다.
이러한 문제를 해결하기 위해 메모리를 효율적으로 사용하면서도 빠르게 특정 원소가 집합에 포함되어있는지 확인이 가능한 BloomFilter라는 자료구조를 도입해보았고, 도입하는 과정에서 BloomFilter에 대해 알아본 내용들을 정리해보려합니다.
이번 글에서 다룰 내용 소개
이번 글에서는 다음과 같은 내용을 다룹니다.
- BloomFilter가 무엇인지
- BloomFilter의 간단한 동작 원리
- Guava 라이브러리를 사용하여 Java에서 BloomFilter를 사용하는 예시
- BloomFilter의 실제 유스케이스 소개
1. BloomFilter의 정의
BloomFilter란 무엇인가?
BloomFilter는 어떤 요소가 집합에 속하는지를 빠르고 효율적으로 확인할 수 있게 도와주는 자료구조입니다. 1970년에 Burton Howard Bloom이 처음 제안한 자료구조이며 메모리를 적게 사용하면서도 빠르게 동작한다는 특징이 있습니다.
BloomFilter의 두 가지 주요 요소
- 비트 배열 : 고정 크기의 비트 배열로, 처음에는 모든 비트가 0으로 설정됩니다.
- 해시 함수 : 여러 개의 해시 함수가 있으며, 각 해시 함수는 입력된 항목을 비트 배열의 특정 위치로 변환합니다.
위 내용은 아래에서 자세히 설명할 것이니 지금은 그렇구나 정도로만 이해해주세요.
BloomFilter의 특징
BloomFilter는 다음과 같은 특징을 가지고 있습니다.
- 빠른 검사 속도 : BloomFilter는 어떤 요소가 집합에 있는지 매우 빠르게 확인할 수 있습니다.
- 메모리 효율성 : BloomFilter는 비트 배열과 해시 함수를 사용하여 적은 메모리로 많은 데이터를 처리할 수 있습니다.
- 확률적 자료구조 : BloomFilter는 False Positive가 발생할 수 있습니다. 즉, 어떤 요소가 집합에 없는데도 있다고 잘못 판단하는 경우가 있습니다. 하지만 False Negative는 발생하지 않습니다. 즉, 어떤 요소가 집합에 없다고 판단하면 실제로도 집합에 요소가 절대 없는 것이죠. 이 이유는 아래에서 동작원리를 살펴보면서 더 자세히 알아보도록 하겠습니다.
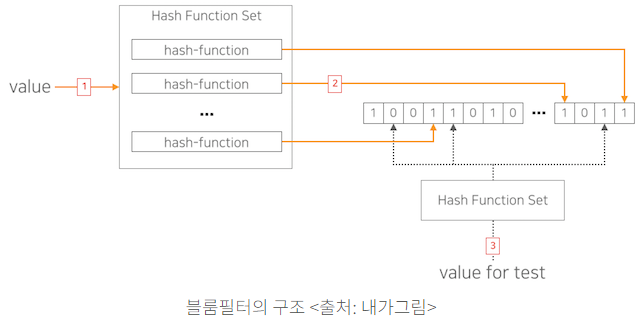
2. BloomFilter의 동작 원리
BloomFilter의 동작
BloomFilter는 크게 두 가지 동작이 있습니다.
- 특정 요소를 집합에 넣는다.
- 특정 요소가 집합에 포함되어있는지 확인한다.
이 두 가지 동작을 메모리 효율적으로, 빠르게 연산하는 자료구조인 것이죠.
BloomFilter의 동작 원리
BloomFilter는 해시 함수와 비트 배열을 사용합니다. 비트 배열은 고정된 크기의 배열로, 처음에는 모든 비트가 0으로 설정됩니다. 또한 해시 함수는 입력된 데이터를 고유한 숫자로 변환해주는 함수입니다. 여러 개의 해시 함수를 사용하여 각 데이터가 비트 배열의 여러 위치에 매핑되도록 합니다.
BloomFilter에서 어떤 요소를 집합에 추가하는 과정은 다음과 같습니다.
- 새로운 요소를 추가할 때, 여러 해시 함수가 요소를 각각 해시하여 비트 배열의 여러 위치를 계산합니다.
- 계산된 각 위치에 해당하는 비트를 1로 설정합니다.
BloomFilter에서 특정 요소가 집합에 속하는지 검사하는 과정은 다음과 같습니다.
- 항목이 BloomFilter에 있는지 확인할 때, 해시 함수들이 항목을 해시하여 비트 배열의 위치를 계산합니다.
- 계산된 위치들의 비트가 모두 1인지 확인합니다. 모든 비트가 1이면, 항목이 존재한다고 판단하고(이때 정확하지 않은 판단이 발생할 수 있음), 하나라도 0이면, 항목이 존재하지 않는다고 판단합니다.
→ 이런 이유로 BloomFilter는 False Positive가 발생할 수 있고, False Negative는 발생할 수 없습니다. 예시를 보면서 좀 더 자세히 알아보죠.
예시와 그림
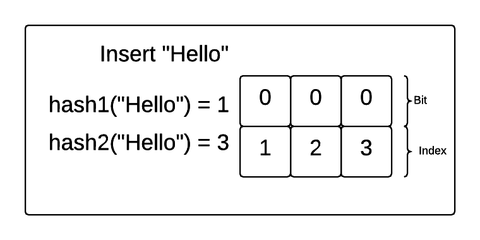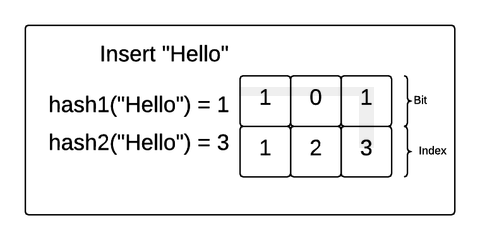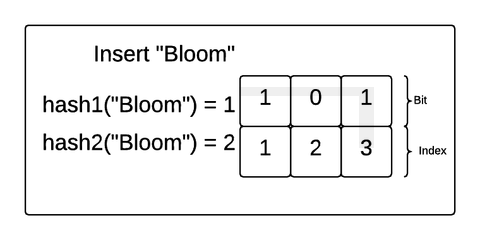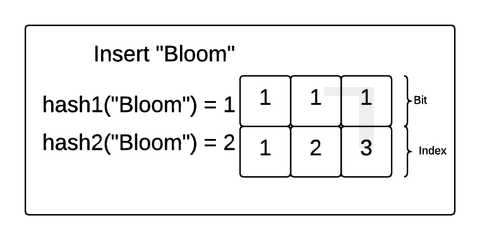
위 그림 두가지는 BloomFilter에 원소를 추가하는 과정을 보여줍니다.
그림에 대해 간단히 설명해보면
- 원소(value)를 준비된 여러 개의 해시함수를 거치게 한다.
- 여러 개의 해시함수는 비트 배열의 인덱스를 결과값으로 낸다.
- 해시함수에서 나온 결과값인 인덱스에 해당하는 비트 배열의 값을 1로 변경시킨다.
그러면 원소가 집합에 존재하는지는 어떻게 알 수 있을까요? 원소 추가와 비슷한 과정을 거칩니다.
- 원소를 여러 개의 해시함수를 거치게 한다.
- 여러 개의 해시함수에서 나온 비트 배열 인덱스를 각각 결과값으로 낸다.
- 비트 배열에서 결과값으로 나온 인덱스 값이 모두 1인지 확인한다.
- 모두 1이라면 원소가 집합에 존재한다고 판단하고, 하나라도 0이라면 존재하지 않는다고 판단한다.
→ 이 과정을 보면 False Positive, 즉 원소가 실제로 집합에 없는데 있다고 판단하는 경우가 생길 것이라는게 감이 조금씩 올 수 있을 것 같습니다.
False Positive가 나올 수 있는 예시
조금 더 쉽게 하기 위해 False Positive가 나오는 예시를 하나 더 설명해보겠습니다.
초기 상태
- 해시 함수: H1, H2, H3
- 초기 비트 배열: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
‘apple’ 항목 추가
- H1('apple') → 위치 3
- H2('apple') → 위치 7
- H3('apple') → 위치 10
- 비트 배열 업데이트
- 위치 3을 1로 설정
- 위치 7을 1로 설정
- 위치 10을 1로 설정
- 업데이트된 비트 배열: [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0]
‘banana’ 항목 추가
- H1('banana') → 위치 5
- H2('banana') → 위치 8
- H3('banana') → 위치 10
- 'banana'가 BloomFilter에 추가된 후 비트 배열: [0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0]
‘grape’가 집합에 있는지 검색
- H1('grape') → 위치 5
- H2('grape') → 위치 7
- H3('grape') → 위치 10
- 비트 배열의 위치 5, 7, 10 모두 1이므로, BloomFilter는 'grape'가 존재한다고 잘못 판단
→ 이것이 False Positive입니다.
이제 False Positive는 존재할 수 있다는 것을 이해하실 수 있으실 것 같고, 조금만 더 생각해보면 False Negative(실제로 원소가 집합에 있는데도 없다고 판단하는 경우)가 존재할 수 없다는 것도 알 수 있을 것 같습니다.
해시 함수와 비트 배열 크기로 False Positive 문제 줄이기
BloomFilter에서 False Positive 문제는 해시 함수의 개수와 비트 배열의 크기 조절로 줄일 수 있습니다. 해시 함수의 개수가 많은수록 데이터가 더 고르게 분포되므로 False Positive 확률이 줄어들고, 비트 배열의 크기가 클수록 위 예시처럼 비트가 겹치는 문제가 줄어드므로 False Positive 확률이 줄어듭니다. 해시 함수 개수는 속도와 정확성의 트레이드 오프이고, 비트 배열 크기는 메모리와 정확성의 트레이드 오프라고 할 수 있겠습니다.
3. Java에서 BloomFilter 사용하기 - Guava 라이브러리
Guava는 Goolge에서 제공하는 오픈 소스 라이브러리인데 이 라이브러리를 이용하면 BloomFilter를 쉽게 사용할 수 있습니다.
사용 예시는 아래와 같습니다.
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample {
public static void main(String[] args) {
// BloomFilter 생성: 예상되는 요소 수와 오차율 설정
BloomFilter<String> bloomFilter = BloomFilter.create(
Funnels.stringFunnel(), 500, 0.01);
// 요소 추가
bloomFilter.put("apple");
bloomFilter.put("banana");
bloomFilter.put("cherry");
// 요소 존재 여부 확인
System.out.println(bloomFilter.mightContain("apple")); // true
System.out.println(bloomFilter.mightContain("grape")); // false
}
}
주요 함수와 메소드
- create(Funnel<T> funnel, long expectedInsertions, double fpp): BloomFilter를 생성합니다. funnel은 데이터를 처리하는 방법을 정의하고, expectedInsertions는 예상되는 요소의 수, fpp는 허용 가능한 오차율을 나타냅니다.
- put(T item): BloomFilter에 요소를 추가합니다.
- mightContain(T item): 요소가 BloomFilter에 있을 가능성을 확인합니다. true 또는 false를 반환합니다.
4. 애플리케이션에서의 BloomFilter 실사용 예시
이제 BloomFilter를 실제 어떻게 사용하는지 유즈케이스들을 살펴보도록 하겠습니다.
Google Chrome
Google Chrome에서는 사용자가 방문하려는 웹사이트가 악성 사이트 목록에 포함되어 있는지 빠르게 확인하기 위해 BloomFilter를 사용한다고 합니다. BloomFilter는 메모리 사용량이 적고, 빠른 검색 속도를 제공하므로, 대규모 악성 사이트 목록을 BloomFilter에 저장하는 것이죠.
그리고 다음과 같은 행위를 하면 정확하게 악성사이트를 체크할 수 있습니다.
- BloomFilter에서 악성사이트 목록이 아니라고 판단한다. → 진짜 악성 사이트 목록에 없는 사이트다.
- BloomFilter에서 악성사이트 목록이 맞다고 판단한다. → False Positive 일 수 있으니 DB 같은 저장소에서 한번 더 확인한다.
이 과정을 통해 빠르게 검사할 수 있게 됩니다.
Disk IO 최적화
BloomFilter를 사용하여 DB I/O 같은 작업을 최적화할 수 있습니다. 예를 들어, 데이터베이스에서 특정 레코드가 존재하는지 확인할 때, BloomFilter를 먼저 검사하여 해당 레코드가 없을 가능성이 높다면 디스크 읽기 작업을 생략할 수 있습니다. 이를 통해 디스크 IO 횟수를 줄이고 전체 시스템 성능을 향상시킬 수 있습니다.
개인화 광고 추천 서비스:
개인화 광고 추천 서비스에서도 BloomFilter를 사용할 수 있습니다. 예를 들어 특정 사용자가 이미 본 광고는 다시 보여주지 않는다라는 요구사항이 있을 때, BloomFilter를 이용하여 사용자가 광고를 볼때마다 해당 광고의 ID를 BloomFilter에 추가하고, 새로운 광고를 추천할 때 BloomFilter를 검사하여 이미 본 광고를 제외할 수 있습니다.
위에서 살펴본 예시와 같이 메모리 측면, 속도 측면에서 BloomFilter를 활용할 수 있는 분야가 많이 존재합니다.
참고자료
- Bloom Filter - 위키백과
- Geeks for Geeks - Bloom Filters Introduction and Python Implementation
- Redis Documentation - Bloom Filter
- 브릴리언트 - Bloom Filter
- 네이버 D2 - 블룸 필터
- 개발 블로그 - Bloom Filter
- Steemit - Bloom Filter
- NHN Cloud Meetup - Bloom Filter
'CS > 자료구조' 카테고리의 다른 글
| [자료구조] 우선순위 큐와 heap (0) | 2021.12.02 |
|---|