
0. 들어가며 🏃🏻♂️
이번 글에서는 JPA를 사용할 때 중요한 개념인 N + 1 문제에 대해 알아보려합니다.
N + 1 문제는 JPA를 처음 공부할 때부터 중요하다고 들었고, 이에 대한 해결법 역시 대략적으로 알고있다고 생각했습니다. 그런데 막상 실제 프로젝트에서 엔티티가 여러 OneToMany, ManyToOne 필드들을 가지게되고 서로 얽혀있다보니 이를 다루는 방법을 잘모르겠어서 애를 먹은 경험을 했습니다.
또한 N + 1 문제를 해결하기 위해 사용하는 방법들이 어떤 쿼리를 날리길래 해당 문제를 해결하는지, 어떤 방식으로 동작하는지에 대해서도 모르고 사용한다는 생각이 강하게 들었습니다.
이를 위해 N + 1 문제에 대해 조금 더 깊게 알아보는 시간을 가져보았고, 이를 정리해보려합니다.
결론부터 말하면 현재 진행 중인 프로젝트에서 N + 1 문제를 해결하기 위해 ManyToOne 필드는 모두 fetch join을 사용했고, OneToMany 필드 즉, 컬렉션 관계에서 N + 1 문제 해결을 위해서는 전역적인 Batch size 설정을 했습니다.
들어가기에 앞서 프로젝트의 엔티티들을 간단한 버전으로 변경하여 테스트 코드를 작성해보려 합니다. 사용한 엔티티 구조는 아래와 같습니다.

간단히 설명하면 Member 엔티티는 Post와 OneToMany 관계가 있으며, Post 엔티티는 PostImage, Comment와 OneToMany 관계가 있는 상황입니다.
1. N + 1 문제란❓
N + 1 문제는 설명보다는 예시를 통해 알아보면 훨씬 쉽게 다가올 것 같습니다. 아래 코드와 사진은 N + 1 문제가 발생한 예시입니다.
@Test
public void NPlusOneProblem() {
Member member1 = new Member("member1");
Member member2 = new Member("member2");
Member member3 = new Member("member3");
em.persist(member1);
em.persist(member2);
em.persist(member3);
Post post1 = new Post("post1");
Post post2 = new Post("post2");
Post post3 = new Post("post3");
member1.addPost(post1);
member2.addPost(post2);
member3.addPost(post3);
em.persist(post1);
em.persist(post2);
em.persist(post3);
em.flush();
em.clear();
System.out.println("=================================================");
// 멤버 전체 조회
List<Member> members = em.createQuery("select m from Member m", Member.class)
.getResultList();
// 멤버의 첫번째 포스트 정보를 가져와보기 -> 이부분이 없으면 LAZY 로딩으로 인해 N + 1 문제 발생안함
for (Member member : members) {
member.getPostList().get(0);
}
System.out.println("=================================================");
}member를 3명 불러오는 쿼리를 날린 뒤 member의 첫번째 post를 조회하는 테스트를 실행해본 결과 아래와 같은 쿼리가 나가게 됩니다.

쿼리를 살펴보면 member를 한 번 조회하고 추가로 3번의 쿼리가 더 나간 것을 확인할 수 있습니다. 첫 쿼리에 불러온 member가 3명이 조회됐고, member의 post를 조회하는 과정에서 member 3명의 post 정보를 불러오기 위해 3번의 쿼리가 더 나간 것이죠.
위 상황을 바로 N + 1 문제가 발생했다고 말합니다. 이 테스트를 보면 4번의 쿼리가 나갔으니 별 문제가 없어보일 수 있지만 만약 조회된 member가 만 명이라고 가정해보면 어떨까요?
첫 쿼리에서 만 명의 멤버를 조회했고, 만 명에 대한 post 정보를 불러오기 위해 만 번의 쿼리가 추가로 실행되어야 하는 상황이 생깁니다. 멤버의 포스트 정보를 조회한 것 뿐인데 10,001번의 쿼리가 나간다..? 성능상 안좋은 결과를 내버리고 말 것 같습니다.
2. 해결법❗️
앞서 소개한 N + 1 문제를 해결하기 위한 방법들은 여러가지가 있지만 이번 글에서는 크게 두 가지 방법을 소개해보려합니다.
1) Fetch Join
먼저 첫 번째 해결법인 fetch join에 대해 알아보도록 하겠습니다. 이 역시 사용한 예시부터 살펴보도록 하겠습니다. 위에서 살펴본 코드에서 멤버 전체 조회 부분만 아래와 같이 수정해주면 됩니다.
// N + 1문제를 해결하기 위해 fetch join을 사용한 멤버 전체 조회
List<Member> members = em.createQuery("select m from Member m join fetch m.postList", Member.class)
.getResultList();위 코드를 살펴보면 join과 비슷한 쿼리를 날리는 것처럼 보입니다. 실제로 fetch join을 사용했을 때 어떤 쿼리가 날아갔는지 아래 사진을 통해 살펴보도록 하죠.
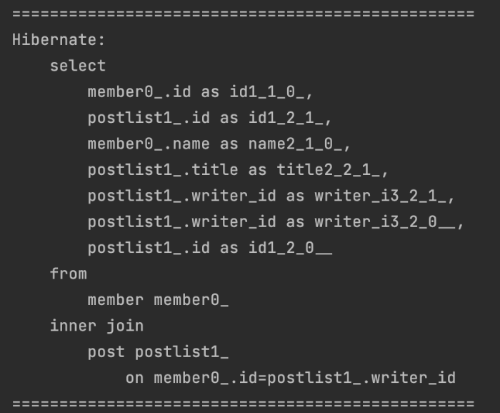
같은 행위를 하는 코드를 실행시켰음에도 불구하고 쿼리가 4번이 아닌 1번만 실행됐죠! N + 1 문제가 발생하지 않은 것입니다!
쿼리를 살펴보면 Post와 inner join한 모습이 보이고 select문 안에 member 정보 외 post 정보까지 가져왔음을 알 수 있습니다. 이것을 살펴보면 그냥 DB에 join 쿼리를 날린 것 같지 않으신가요?
그래서 그냥 inner join 쿼리도 한번 날려보았습니다.
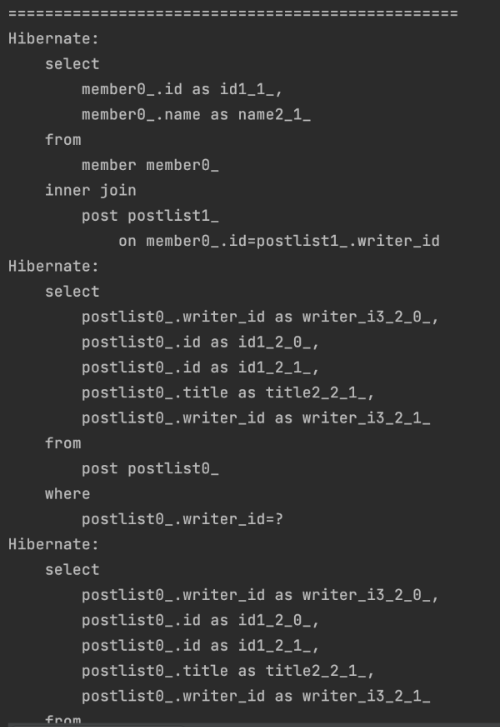
inner join만을 사용해서 쿼리를 날려보았더니 select 문에 member 정보만 가져오게 되고, 사진에서는 잘렸지만 N + 1 문제가 발생한 것을 확인할 수 있습니다.
+ 추가로 그렇다면 inner join + select 절에 post까지 추가해 쿼리를 날려볼 순 있지 않을까 생각이 들어 시도해봤는데 이 부분은 JPA에서 허용하지 않는지 에러가 났습니다. 해당 부분은 왜 되지않는 건지 정확한 이유를 모르겠어서 추후 공부해보고 내용을 추가해보도록 하겠습니다. 혹시 이유를 아신다면 댓글로 남겨주시면 감사하겠습니다..ㅎ
2) Batch Size 설정
N + 1 문제를 해결하기 위한 두 번째 방법으로는 Batch Size 설정이 있습니다. batch size는 전역적으로 설정할 수도 있고, 개별적으로 설정할 수도 있습니다. 이번 글에서는 아래와 같이 yml 파일에 전역 설정을 한 뒤 batch size가 설정되어 있으면 어떻게 동작하는지 살펴보도록 하겠습니다. 우선 아래와 같은 설정을 yml 파일에 추가해보겠습니다.
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 100이후 처음 실행시켰던 (N + 1 문제가 발생한) 코드를 그대로 실행시켜보겠습니다.
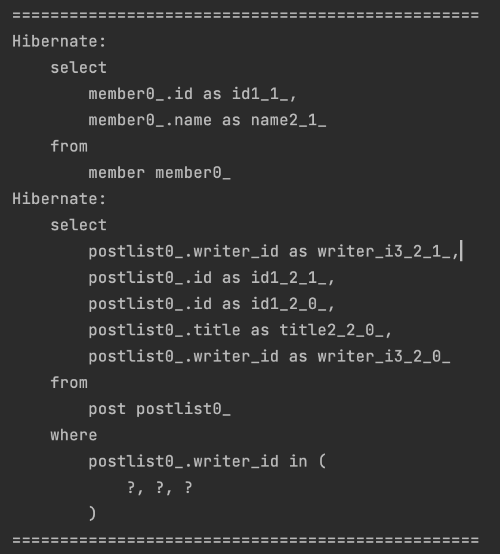
총 2개의 쿼리가 나간걸 확인할 수 있죠. Batch size를 설정하지 않았을 때는 N + 1 문제로 인해 총 4번의 쿼리가 나간 것과 비교됩니다. 첫번째 쿼리는 멤버를 조회한 쿼리이므로 동일하고 주의깊게 보셔야할 부분은 두번째 쿼리입니다. post 정보를 가져오는데 in 쿼리가 추가된 모습을 확인할 수 있습니다. batch size는 바로 이 in 쿼리 안 조건문에 들어갈 수 있는 writer_id 수가 됩니다. 현재는 100으로 설정했으니 in 쿼리 안에 최대 100개의 member id값이 들어갈 수 있을 것이고 이로 인해 나가야할 쿼리의 수를 줄일 수 있게 됩니다. 지금은 데이터가 많지 않아 극적인 효과를 보지 못했지만, 만약 첫 번째 쿼리로 조회된 member가 1,000명이었다면 총 나가는 쿼리가 1,001번의 쿼리 에서 11번 (1 + 1000 / 100) 의 쿼리로 줄어들게 됩니다.
그렇다면.. fetch join 쓰면 되지 왜 batch size 쓰냐! 라는 궁금증이 생길 수도 있을 것 같습니다.
그러나 fetch join에는 몇 가지 한계가 있습니다. 이 부분 역시 알아보도록 하겠습니다.
3. Fetch Join의 한계와 Batch size 개념도 필요한 이유 🤔
fetch join의 한계가 있어 Batch size를 사용해야할 경우도 있다고 말씀드렸는데, 이 부분에 대해 알아보도록 하겠습니다.
fetch join의 경우 ManyToOne 관계에서는 자유롭게 사용해도 되지만 OneToMany 관계를 fetch join 할때는 제약이 생깁니다. 아래 예시를 살펴보도록 하죠.
@Test
public void OneToMany_관계를_fetch_join_여러번_하는_경우() {
Member member1 = new Member("member1");
Member member2 = new Member("member2");
Post post1 = new Post("post1");
Post post2 = new Post("post2");
Post post3 = new Post("post3");
member1.addPost(post1);
member2.addPost(post2);
member2.addPost(post3);
Comment comment1 = new Comment("comment1", member1);
Comment comment2 = new Comment("comment2", member1);
Comment comment3 = new Comment("comment3", member2);
post1.addComment(comment1);
post2.addComment(comment2);
post3.addComment(comment3);
PostImage postImage1 = new PostImage("image1");
PostImage postImage2 = new PostImage("image2");
PostImage postImage3 = new PostImage("image3");
post1.addPostImage(postImage1);
post2.addPostImage(postImage2);
post3.addPostImage(postImage3);
em.persist(member1);
em.persist(member2);
em.persist(post1);
em.persist(post2);
em.persist(post3);
em.flush();
em.clear();
System.out.println("=================================================");
// OneToMany 관계인 컬렉션 두개를 fetch join 하는 경우 -> 에러!
List<Post> posts = em.createQuery(
"select p from Post p " +
"join fetch p.comments " +
"join fetch p.postImages", Post.class
)
.getResultList();
System.out.println("=================================================");
}위와 같이 Post 기준으로 OneToMany 관계인 두 컬렉션을 같이 join fetch 하는 경우 다음과 같은 에러가 납니다.

위와 같은 에러는 왜 나게되는걸까요? 제가 나름 생각해본 이유는 다음과 같습니다.
OneToMany 관계를 join fetch 하게 되면 DB 조회 결과물의 Row수가 증가합니다. 아래 그림과 같이 말이죠!
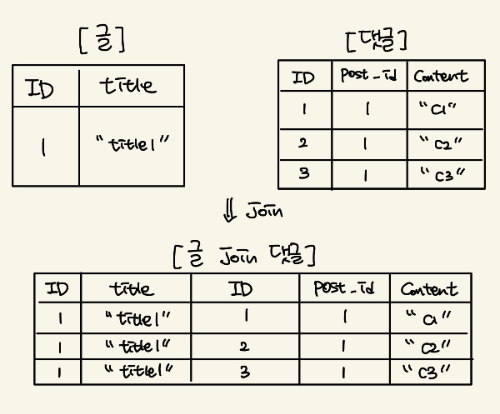
위와 같은 상황은 우리가 보통 애플리케이션 메모리 상에서 원하는 결과와 미묘하게 다릅니다.
자바 코드 상에서는 글 객체 하나 + 글 객체 안 필드인 댓글 컬렉션에 값이 3개여야하는 상황이 DB의 Row가 3개여서 글 객체가 마치 세개처럼 보이는 상황과 다르듯 말이죠.
이 간극을 메꾸기 위해서 JPQL의 Distinct 키워드 라는 해결책을 가지고 있습니다. DB에서의 distinct 키워드와는 비슷하나 조금 다르게 동작하는데요. JPQL의 distinct 는 기본적으로 SQL에 distinct 키워드를 추가해줌과 더불어 애플리케이션에서 엔티티 중복을 제거해줍니다. 즉, DB와 객체지향 프로그래밍에서의 간극을 매꿔줌으로써 자바 코드를 쓰는 개발자가 편하게 객체입장에서 생각하며 코드를 쓸 수 있게 해줍니다.
여기까지는 좋습니다. 하지만 OneToMany를 두 번 이상 fetch join하게 되면 Data 양이 너무 많이 불어날 가능성이 존재합니다. 1 X N X N 식에 Data 뻥튀기는 부담스러워지고, 여기에 distinct 같은 기능을 적용하기 껄끄러워 질 것 같습니다. JPA는 이러한 이유로 OneToMany 관계 즉, 컬렉션은 두 개 이상 fetch join 시키지 않도록 정해놓은게 아닐까라고 생각합니다. 이 부분은 개인적으로 그렇지 않을까라고 생각해본 부분이라 틀린 내용이라면 댓글에 남겨주시면 감사하겠습니다..ㅎ
fetch join은 OneToMany 관계(컬렉션)을 두 번 이상 fetch join 할 수 없다는 점과 더불어 OneToMany 관계 fetch join을 할 때 사용하지 못하는 기능이 하나 더 있습니다.
바로 페이징입니다. 만약 Post를 OneToMany 관계인 comment와 fetch join한 뒤 페이징을 위해 50개 데이터만 가져오세요! 라는 쿼리를 날렸다고 가정해봅시다. 이러면 앞서 살펴본 DB 데이터 Row 증가로 인해 Post 50개를 가져오는 동작이 이상하게 작동할 것입니다. 각기 다른 Post 50개를 가져와야하는데 DB Row를 기준으로 50개를 가져왔다? 이러면 사실상 서로 다른 Post 50개가 아닌것이죠. 그렇기 때문에 JPA는 DB에 있는 Post 전부를 가져온 뒤 애플리케이션 메모리에서 페이징을 해버립니다. 데이터 뻥튀기가 일어나고 나면 몇 개의 Row를 가져와야 서로 다른 Post 50개를 가져올 수 있을지 판단할 수가 없기 때문입니다. 이러한 상황 자체가 상당히 위험하기 때문에 동작은 하되 하이버네이트에서 경고 로그를 남깁니다. 잘 알고 써야하는 부분인 것이죠.
위와 같은 점들을 살펴보면 결코 fetch join이 만능은 아님을 알 수 있고 적절한 상황에 fetch join을 사용함과 동시에 batch size라는 개념이 필요함을 알 수 있습니다.
4. 나가며 💨
이번 글에서는 JPA를 사용하다보면 누구나 마주칠 수 있는 N + 1 문제에 대해 알아보았습니다. 개념을 알고 있는 것과 실전에서 써먹을 수 있는 것이 다르다는 것을 또 한 번 느낀 것 같고, 제대로 알지 못하고 쓰면 어떤 위험한 점이 있는지조차 모를 수 있겠구나라는 생각을 하게 되었습니다. 앞으로도 좀 더 깊게 공부하는 습관을 들여야겠다는 것을 다시 한번 새기게 되는 계기가 되었네요.
긴 글 읽어주셔서 감사합니다.
'Spring > JPA' 카테고리의 다른 글
| [Spring] JPA OptimisticLock은 락을 잡지 않는가? (0) | 2025.03.09 |
|---|---|
| [JPA] findByXXX 와 findByXXXId 에서 생기는 차이 (0) | 2023.08.05 |