[Spring] 동시성 이슈 해결하는 방법 찍먹하기
0. 들어가며 🏃🏻♂️
평소 동시성 이슈에 대해 알고는 있었으나, 이를 어떻게 해결하는지 이론적으로만 알고 있다고 생각하여 코드상으로는 어떻게 구현할 수 있는지에 대해 알아보기 위해 공부하였고, 이에 대한 내용을 정리해보려합니다.
전체적으로 인프런의 재고시스템으로 알아보는 동시성이슈 해결방법 강의를 참고하였습니다.
1. 전체 개요 📖
우선 글에서 가정이 되는 상황을 먼저 소개하겠습니다. 어떤 물품을 판매한다고 가정했을 때 물품의 수량이 있을 것이고, 소비자가 물품을 사는 행위를 할 때마다 Stock entity에 decrease 메서드를 통해 수량을 감소시키는 간단한 상황을 생각해보겠습니다.
@Entity
public class Stock {
private Long quantity;
public void decrease(Long quantity) {
if (this.quantity - quantity < 0) {
throw new RuntimeException("재고가 부족합니다.");
}
this.quantity -= quantity;
}
}위 코드는 보기 쉽도록 간단하게 Stock Entity에서 필요한 부분만 발췌했습니다.
또한 이를 호출하는 Service Layer의 코드도 간단하게 소개하겠습니다.
@Service
public class StockService {
private StockRepository stockRepository;
public StockService(StockRepository stockRepository) {
this.stockRepository = stockRepository;
}
@Transactional
public void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findById(id).orElseThrow();
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}
decrease 메서드가 잘 정의된 것 같고, Service Layer도 딱히 문제가 없어보이나 여기서 발생할 수 있는 문제가 있습니다. 바로 동시성 문제이죠. 물품을 주문하는 사람들이 많아져 동시에 여러 쓰레드가 decrease 메서드를 부르게 된다면 아래와 같은 문제들이 발생할 가능성이 생깁니다.

위 그림을 보시면 decrease 메서드가 두 쓰레드에서 각각 한 번씩, 즉 총 두 번 불렸음에도 수량은 하나밖에 깎이지 않는 모습을 볼 수 있습니다. 이런 문제를 동시성 이슈라고 하는데 정말 발생하는지 테스트를 해보겠습니다.
테스트는 아래와 같이 진행했습니다.
@BeforeEach
public void setUp() {
Stock stock = new Stock(1L, 1L, 100L);
stockRepository.saveAndFlush(stock);
time = System.currentTimeMillis();
}
@Test // 256 ms
public void 동시에_100개의_요청시_실패() throws InterruptedException {
int decreaseCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(decreaseCount);
for (int i = 0; i < decreaseCount; i++) {
executorService.submit(() -> {
try {
stockService.decrease(1L, 1L);
} finally {
latch.countDown();
}
});
}
latch.await();
Stock stock = stockRepository.findById(1L).orElseThrow();
assertEquals(0L, stock.getQuantity());
}위 코드는 여러 쓰레드를 가지고 동시에 물품의 수량을 줄이는 코드인데요. 이 코드의 결과는 다음과 같았습니다.
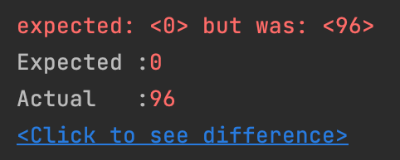
초기 Stock의 수량을 100개로 지정했고, 100번의 decrease를 호출했으니 이에 Stock의 수량이 0이 되었을 것이라고 예상했는데 결과는 0이 아닌 96이 나왔습니다. 위에서 살펴본 것처럼 실제로 동시성 문제가 발생해버린 것이죠.
그렇다면 동시성 문제는 어떻게 해결해야할까요? 여러 방법이 있겠지만 저는 다음과 같은 방법을 사용해 동시성 문제를 해결하려하고 그 과정에서 Service Layer의 decrease 메서드를 조금씩 수정해보려 합니다.
1. Java의 Synchronized 키워드 사용하기
2. DB에서 해결하기
3. Redis를 사용해 해결하기
그럼 시작해보도록 하겠습니다.
2. Synchronized ⭐️
우선 Java 공부를 하다보면 Synchronized 키워드에 대해 알 수 있는데 이 키워드를 붙이게 되면 Thread safe하도록 메서드를 처리해주는 역할을 합니다. 그럼 한 번 붙여보도록하죠!
// @Transactional
public synchronized void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findById(id).orElseThrow();
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}기존 Service Layer의 decrease 메서드에 synchronized 키워드를 붙여보았습니다. 이 때 주의할 점은 Transactional 어노테이션을 붙이게되면 Spring AOP로 인해 원자적으로 메서드가 동작하지 않아 예상대로 동작하지 않기 때문에 떼어줘야합니다.
그리고 위에서 했던 테스트를 그대로 해보면..

위처럼 제대로 동작하는 것을 알 수 있습니다!
하지만 여기서도 문제가 있는데요.. synchronized 키워드는 하나의 프로세스에서만 Thread safe함이 보장됩니다. 따라서 만약 서버가 한대라면 괜찮지만, 서버가 두 대 이상인 경우 공유하는 데이터에 대해 여러 프로세스가 동시에 접근하게 되고 이에 따라 동시성 문제가 여전히 발생하게 됩니다. 또한 실제 운영 중인 서비스들은 대부분 서버가 여러 대이기 때문에 이 방법으로는 해결이 어렵겠네요.
3. Database 활용 📚
그렇다면 이번에는 DB를 통해 동시성 문제를 해결해보도록 하겠습니다.
1) Pessimistic Lock (비관적 락)
Pessimistic Lock은 비관적락으로도 많이 불리는데, 이는 실제로 데이터에 Lock을 걸어서 정합성을 맞추는 방법입니다. 공유락 혹은 배타락을 걸게되면 다른 트랜잭션에서 데이터를 가져갈 수 없기 때문에 이를 통해 동시성 문제를 해결할 수 있습니다. 한 번 코드로 살펴보도록 하죠.
비관적락 설정을 하기 위해서는 Repository Layer를 건드려야하는데 아래처럼 코드를 추가해줍니다.
public interface StockRepository extends JpaRepository<Stock, Long> {
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("select s from Stock s where s.id = :id")
Stock findByIdWithPessimisticLock(Long id);
}@Lock 어노테이션과 value 값을 위와 같이 설정해줌으로써 비관적 락을 걸 수 있게 됩니다. 여기서는 배타락을 특정 id값의 stock에 걸고, 트랜잭션이 stock에 대한 처리를 다 한 뒤 락을 반납하도록 동작합니다. 이러한 방식으로 동시성 문제를 해결하는 것이죠.
Service Layer는 다음과 같이 코드를 변경해줍니다.
@Transactional
public void pessimisticDecrease(Long id, Long quantity) {
Stock stock = stockRepository.findByIdWithPessimisticLock(id);
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}이렇게 변경하고 테스트를 진행해보면..

위처럼 테스트를 잘 통과하는 것을 볼 수 있습니다.
비관적 락을 사용하는 경우 데이터 정합성은 잘 지켜지지만 이에 따른 성능감소가 있어 이를 잘 고려한 뒤 사용해야합니다.
2) Optimistic Lock (낙관적 락)
다음은 낙관적락으로도 불리는 Optimistic Lock 방법입니다. 이 방식은 실제로는 Lock을 걸지 않고 버전값을 이용해 정합성을 맞추는 방식입니다. Pessimistic Lock과는 다르게 제약없이 데이터를 버전값과 함께 읽은 후 update를 수행하고, 처음 읽었던 버전값과 현재 버전값이 맞는지 확인합니다. 이 때 버전값이 동일하다면 업데이트하고, 버전값이 다르다면 롤백한 뒤 application에서 지정해준 재시도 로직을 사용하게 됩니다.
이 방식을 위해서는 Entity에 Version 컬럼을 추가해야합니다. 아래와 같이 말이죠.
@Entity
public class Stock {
@Version
private Long version; // optimistice lock을 위해 version column 추가!
private Long quantity;
public void decrease(Long quantity) {
if (this.quantity - quantity < 0) {
throw new RuntimeException("재고가 부족합니다.");
}
this.quantity -= quantity;
}
}그 후, 아래와 같이 Service Layer 코드를 변경해줍니다. 재시도 로직을 개발자가 직접 추가해주는 것이죠.
public void optimisticDecrease(Long id, Long quantity) throws InterruptedException {
while (true) { // 실패시 재시도 로직
try {
Stock stock = stockRepository.findByIdWithOptimisticLock(id);
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
break;
} catch (Exception e) {
Thread.sleep(50);
}
}
}위와 같이 코드를 적용해주고 테스트해보면..

위처럼 잘 성공하는 것을 볼 수 있습니다.
낙관적 락의 경우 비관적 락과는 다르게 실제로 락을 걸지 않고 version을 이용하여 성능상에 이점이 있습니다. 다만 재시도 로직을 개발자가 직접 작성해야하는 번거로움이 있죠. 또한 충돌이 빈번하게 발생하는 경우 계속하여 롤백이 일어나기 때문에 오히려 락을 잡는 방식보다도 성능이 안나올 수 있습니다. 따라서 충돌이 얼마나 빈번한지에 따라서 어떤 방식을 사용할지 고민해보아야 합니다.
3) Named Lock
이번에는 Named Lock 방식을 살펴보도록 하겠습니다. 이 방식은 테이블이나 레코드에 락을 거는 방식이 아닙니다. 즉, Stock에 락을 거는 게 아니고 사용자가 지정한 문자열을 DB 메모리에 두고 이에 대한 락을 흭득하고 반납하는 방식입니다. 해당 락을 흭득한 후 해제할때 까지 다른 세션이 이 Lock을 흭득할 수 없도록 하는 것이죠.
코드를 살펴보도록 하죠. 우선 lock을 걸고 해제하는 repository를 하나 만들어줍니다.
public interface LockRepository extends JpaRepository<Stock, Long> {
@Query(value = "select get_lock(:key, 10)", nativeQuery = true)
void getLock(String key);
@Query(value = "select release_lock(:key)", nativeQuery = true)
void releaseLock(String key);
}위와 같이 코드를 작성한 뒤 Service Layer를 수정해줍니다.
@Transactional
public void namedLockDecrease(Long id, Long quantity) {
try {
lockRepository.getLock("stock");
stockService.decrease(id, quantity);
} finally {
lockRepository.releaseLock("stock");
}
}코드를 살펴보면 먼저 문자열 "stock"에 대한 락을 흭득한 뒤 필요한 행위를 해주고, lock을 해제하는 과정을 거치는 것을 알 수 있습니다. 이처럼 Named Lock은 트랜잭션이 종료될 때 자동으로 해제되지 않기 때문에 별도의 명령어로 해제하거나 선점시간을 설정해야합니다.
4. Redis 활용 📮
이번에는 Redis를 통해 동시성 이슈를 해결하는 방법을 살펴보도록 하겠습니다. Redi는 키-값 저장소라고 알고있었는데.. 어떻게 Redis를 통해 동시성 이슈를 해결할 수 있을까요? 바로 Redis를 통해 분산락을 활용하면 되는데요. 분산락은 여러 서버 혹은 여러 DB에서도 동시성을 제어할 수 있는 방법입니다. Named Lock과도 비슷한데 예제를 통해 알아보도록 하겠습니다. 크게 Lettuce, Redisson을 사용하는 선택지가 있는 것 같은데 살펴보도록 하죠.
우선 Redis와 Redisson을 사용하기 위해 아래와 같은 의존성을 추가해줍니다.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.redisson:redisson-spring-boot-starter:3.22.0'1) Lettuce
우선 Lettuce로 분산락을 구현하게되면 스핀락 형태를 띠게 됩니다. 락을 흭득하기 위해 SETNX(Set if Not eXist) 라는 명령어로 계속해서 Redis에 락 흭득 효청을 보내는 구조이죠. NamedLock과 비슷하지만 redis를 사용한다는 점과 세션관리에 신경을 쓰지 않아도 된다는 장점이 있습니다. 또한 구현이 간단하죠.
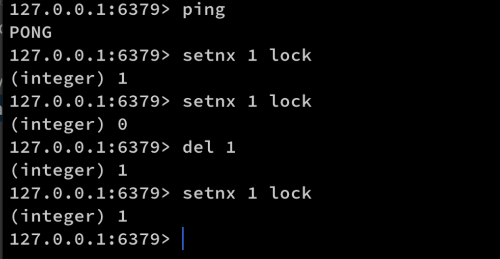
위 사진은 실제로 레디스 서버에 접속하여 setnx 명령어를 통해 락을 흭득하려고 명령어를 쳐본 모습입니다.
이제 Lettuce를 이용한 코드를 간단히 살펴보도록 하겠습니다. 먼저 RedisLockRepository를 아래와 같이 만들어줍니다.
@Component
public class RedisLockRepository {
private RedisTemplate<String, String> redisTemplate;
public RedisLockRepository(RedisTemplate<String, String> redisTemplate) {
this.redisTemplate = redisTemplate;
}
public Boolean lock(Long key) {
return redisTemplate
.opsForValue()
.setIfAbsent(generateKey(key), "lock", Duration.ofMillis(3_000));
}
public Boolean unlock(Long key) {
return redisTemplate.delete(generateKey(key));
}
private String generateKey(Long key) {
return key.toString();
}
}그 후 decrease 메서드를 아래와 같이 변경해줍니다.
public void lettuceLockDecrease(Long key, Long quantity) throws InterruptedException {
while (!redisLockRepository.lock(key)) {
Thread.sleep(100);
}
try {
stockService.decrease(key, quantity);
} finally {
redisLockRepository.unlock(key);
}
}위 코드를 살펴보면 먼저 redis에서 락 얻기를 시도한 뒤, 락을 얻게되면 decrease하고 그 후, 락을 해제하는 모습을 볼 수 있습니다.
이 코드를 토대로 같은 테스트를 실행해보면..

이번에도 성공하는 모습을 살펴볼 수 있습니다!
Lettuce 방식의 경우 구현이 간단하다는 장점이 있음에도 spin lock 방식이기 때문에 Redis에 부하를 줄 수 있습니다. 따라서 lock 흭득 실패 후 재시도 간격을 두는 것도 좋은 방법이라고 합니다.
2) Redisson
Redisson 방식은 Lettuce와 다르게 pub-sub 방식을 사용합니다. redis는 publish를 통해서 자신이 lock을 해제할 때 채널에 메시지를 보냄으로써 락을 흭득해야하는 쓰레드들에게 메시지를 전달합니다. 이런 방식을 통해 redis에 부하가 줄어들게 되죠. 코드를 살펴보도록 하겠습니다.
decrease 메서드만 아래와 같이 변경해주면 됩니다!
public void decrease(Long key, Long quantity) {
RLock lock = redissonClient.getLock(key.toString());
try {
boolean available = lock.tryLock(10, 1, TimeUnit.SECONDS);
if (!available) {
System.out.println("lock 획득 실패");
return;
}
stockService.redissonLockDecrease(key, quantity);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}이렇게 작성해주고 테스트를 돌리면 역시 성공하는 것을 볼 수 있습니다.

이러한 Reddison 방식은 락 흭득 재시도를 기본으로 제공하며, spin lock에 비해 부하가 덜 가는 장점이 있으나 별도의 라이브러리를 사용해야하는 단점이 있습니다.
5. 나가며 💨
이번 글에서는 동시성 이슈를 해결하는 방법을 간단하게 알아보았습니다. 막연하게만 알고있던 동시성 이슈 해결법에 대해 직접 코드를 써보면서 적용해보니 좀 더 와닿는 부분이 있었던 것 같습니다. 다만 각 해결법이 어떤 장단점이 있는지, 기술적으로 선택하는 기준은 무엇인지에 대한 내용을 좀 공부해봐야겠다는 생각이 드는 것 같습니다.
블로그 글을 작성하며 조금 더 심화된 내용이 있던 글들을 발견했는데 추후 참고하는 용도로 남겨두면서 글을 마치도록 하겠습니다.
감사합니다.
MySQL을 이용한 분산락으로 여러 서버에 걸친 동시성 관리 | 우아한형제들 기술블로그
{{item.name}} 안녕하세요. 비즈인프라개발팀 권순규입니다. 현재 광고시스템에서 사용하고 있는 MySQL을 이용한 분산락에 대해 설명드리고자 합니다. 분산락을 적용하게된 원인 현재 테이블은 아래
techblog.woowahan.com
Redis를 활용하여 동시성 문제 해결하기
Redis 분산 락으로 동시성 문제를 해결해봅시다
velog.io
동시성 그리고 정합성, 문제 해결기
쿼리 개선기 에서 알 수 있듯이, F12는 데이터베이스 조회 성능을 개선하고자 product 테이블과 member 테이블에 집계 컬럼을 추가하게 되었습니다. 따로 캐시 계층이나 조회용 NoSQL을 두지 않았기 때
velog.io